



It’s 2018 already, and countless front-end developers are still leading a battle against complexity and immobility. Month after month, they've searched for the holy grail: a bug-free application architecture that will help them deliver quickly and with high quality. I am one of those developers, and I’ve found something interesting that might help.
We have taken a good step forward with tools such as React and Redux. However, they’re not enough on their own in large-scale applications. This article will introduce to you the concept of state machines in the context of front-end development. You’ve probably built several of them already without realizing it.
An Introduction To State Machines
A state machine is a mathematical model of computation. It’s an abstract concept whereby the machine can have different states, but at a given time fulfills only one of them. There are different types of state machines. The most famous one, I believe, is the Turing machine. It is an infinite state machine, which means that it can have a countless number of states. The Turing machine does not fit well in today’s UI development because in most cases we have a finite number of states. This is why finite state machines, such as Mealy and Moore, make more sense.
The difference between them is that the Moore machine changes its state based only on its previous state. Unfortunately, we have a lot of external factors, such as user interactions and network processes, which means that the Moore machine is not good enough for us either. What we are looking for is the Mealy machine. It has an initial state and then transitions to new states based on input and its current state.
One of the easiest ways to illustrate how a state machine works is to look at a turnstile. It has a finite number of states: locked and unlocked. Here is a simple graphic that shows us these states, with their possible inputs and transitions.
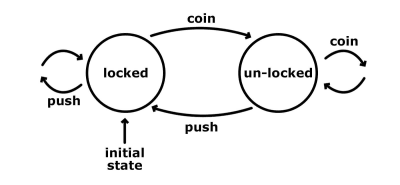
The initial state of the turnstile is locked. No matter how many times we may push it, it stays in that locked state. However, if we pass a coin to it, then it transitions to the unlocked state. Another coin at this point would do nothing; it would still be in the unlocked state. A push from the other side would work, and we’d be able to pass. This action also transitions the machine to the initial locked state.
If we wanted to implement a single function that controls the turnstile, we would probably end up with two arguments: the current state and an action. And if you use Redux, this probably sounds familiar to you. It is similar to the well-known reducer function, where we receive the current state, and based on the action’s payload, we decide what will be the next state. The reducer is the transition in the context of state machines. In fact, any application that has a state that we can somehow change may be called a state machine. It’s just that we are implementing everything manually over and over again.
How Is A State Machine Better?
At work, we use Redux, and I’m quite happy with it. However, I’ve started seeing patterns that I don’t like. By “don’t like,” I don’t mean that they don’t work. It is more that they add complexity and forces me to write more code. I had to undertake a side project in which I had room to experiment, and I decided to rethink our React and Redux development practices. I started making notes about the things that concerned me, and I realized that a state machine abstraction would really solve some of these problems. Let’s jump in and see how to implement a state machine in JavaScript.
We will attack a simple problem. We want to fetch data from a back-end API and display it to the user. The very first step is to learn how to think in states, rather than transitions. Before we get into state machines, my workflow for building such a feature used to look something like this:
- We display a fetch-data button.
- The user clicks the fetch-data button.
- Fire the request to the back end.
- Retrieve the data and parse it.
- Show it to the user.
- Or, if there is an error, display the error message and show the fetch-data button so that we can trigger the process again.

We are thinking linearly and basically trying to cover all possible directions to the final result. One step leads to another, and quickly we would start branching our code. What about problems like the user double-clicking the button, or the user clicking the button while we are waiting for back end’s response, or the request succeeding but the data being corrupted. In these cases, we would probably have various flags that show us what happened. Having flags means more if clauses and, in more complex apps, more conflicts.

This is because we are thinking in transitions. We are focusing on how these transitions happen and in what order. Focusing instead on the application’s various states would be a lot simpler. How many states do we have, and what are their possible inputs? Using the same example:
- idle
In this state, we display the fetch-data button, sit and wait. The possible action is:- click
When the user clicks the button, we are firing the request to the back end and then transition the machine to a “fetching” state.
- click
- fetching
The request is in flight, and we sit and wait. The actions are:- success
The data arrives successfully and is not corrupted. We use the data in some way and transition back to the “idle” state. - failure
If there is an error while making the request or parsing the data, we transition to an “error” state.
- success
- error
We show an error message and display the fetch-data button. This state accepts one action:- retry
When the user clicks the retry button, we fire the request again and transition the machine to the “fetching” state.
- retry
We’ve described roughly the same processes, but with states and inputs.
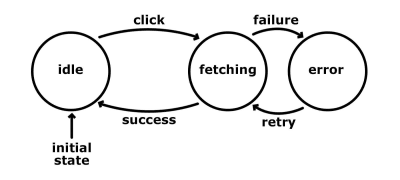
This simplifies the logic and makes it more predictable. It also solves some of the problems mentioned above. Notice that, while we are in “fetching” state, we are not accepting any clicks. So, even if the user clicks the button, nothing will happen because the machine is not configured to respond to that action while in that state. This approach automatically eliminates the unpredictable branching of our code logic. This means we will have less code to cover while testing. Also, some types of testing, such as integration testing, can be automated. Think of how we would have a really clear idea of what our application does, and we could create a script that goes over the defined states and transitions and that generates assertions. These assertions could prove that we’ve reached every possible state or covered a particular journey.
In fact, writing down all possible states is easier than writing all possible transitions because we know which states we need or have. By the way, in most cases, the states would describe the business logic of our application, whereas transitions are very often unknown in the beginning. The bugs in our software are a result of actions dispatched in a wrong state and/or at the wrong time. They leave our app in a state that we don’t know about, and this breaks our program or makes it behave incorrectly. Of course, we don’t want to be in such a situation. State machines are good firewalls. They protect us from reaching unknown states because we set boundaries for what can happen and when, without explicitly saying how. The concept of a state machine pairs really well with a unidirectional data flow. Together, they reduce code complexity and clear the mystery of where a state has originated.
Creating A State Machine In JavaScript
Enough talk — let’s see some code. We will use the same example. Based on the list above, we will start with the following:
const machine = {
'idle': {
click: function () { ... }
},
'fetching': {
success: function () { ... },
failure: function () { ... }
},
'error': {
'retry': function () { ... }
}
}
We have the states as objects and their possible inputs as functions. The initial state is missing, though. Let’s change the code above to this:
const machine = {
state: 'idle',
transitions: {
'idle': {
click: function() { ... }
},
'fetching': {
success: function() { ... },
failure: function() { ... }
},
'error': {
'retry': function() { ... }
}
}
}
Once we define all of the states that make sense to us, we are ready to send the input and change state. We will do that by using the two helper methods below:
const machine = {
dispatch(actionName, ...payload) {
const actions = this.transitions[this.state];
const action = this.transitions[this.state][actionName];
if (action) {
action.apply(machine, ...payload);
}
},
changeStateTo(newState) {
this.state = newState;
},
...
}
The dispatch function checks whether there is an action with the given name in the current state’s transitions. If so, it fires it with the given payload. We are also calling the action handler with the machine as a context, so that we can dispatch other actions with this.dispatch(<action>) or change the state with this.changeStateTo(<new state>).
Following the user journey of our example, the first action we have to dispatch is click. Here is what the handler of that action looks like:
transitions: {
'idle': {
click: function () {
this.changeStateTo('fetching');
service.getData().then(
data => {
try {
this.dispatch('success', JSON.parse(data));
} catch (error) {
this.dispatch('failure', error)
}
},
error => this.dispatch('failure', error)
);
}
},
...
}
machine.dispatch('click');
We first change the state of the machine to fetching. Then, we trigger the request to the back end. Let’s assume we have a service with a method getData that returns a promise. Once it is resolved and the data parsing is OK, we dispatch success, if not failure.
So far, so good. Next, we have to implement success and failure actions and inputs under the fetching state:
transitions: {
'idle': { ... },
'fetching': {
success: function (data) {
// render the data
this.changeStateTo('idle');
},
failure: function (error) {
this.changeStateTo('error');
}
},
...
}
Notice how we’ve freed our brain from having to think about the previous process. We don’t care about user clicks or what is happening with the HTTP request. We know that the application is in a fetching state, and we are expecting just these two actions. It is a little bit like writing new logic in isolation.
The last bit is the error state. It would be nice if we provided that retry logic so that the application can recover from failure.
transitions: {
'error': {
retry: function () {
this.changeStateTo('idle');
this.dispatch('click');
}
}
}
Here we have to duplicate the logic that we wrote in the click handler. To avoid that, we should either define the handler as a function accessible to both actions, or we first transition to the idle state and then dispatch the click action manually.
A full example of the working state machine can be found in my Codepen.
Managing State Machines With A Library
The finite state machine pattern works regardless of whether we use React, Vue or Angular. As we saw in the previous section, we can easily implement a state machine without much trouble. However, sometimes a library provides more flexibility. Some of the good ones are Machina.js and XState. In this article, however, we will talk about Stent, my Redux-like library that bakes in the concept of finite state machines.
Stent is an implementation of a state machines container. It follows some of the ideas in the Redux and Redux-Saga projects, but provides, in my opinion, simpler and boilerplate-free processes. It is developed using readme-driven development, and I literally spent weeks only on the API design. Because I was writing the library, I had the chance to fix the problems that I encountered while using the Redux and Flux architectures.
Creating Machines
In most cases, our applications cover multiple domains. We can’t go with just one machine. So, Stent allows for the creation of many machines:
import { Machine } from 'stent';
const machineA = Machine.create('A', {
state: ...,
transitions: ...
});
const machineB = Machine.create('B', {
state: ...,
transitions: ...
});
Later, we can get access to these machines using the Machine.get method:
const machineA = Machine.get('A');
const machineB = Machine.get('B');
Connecting The Machines To The Rendering Logic
Rendering in my case is done via React, but we can use any other library. It boils down to firing a callback in which we trigger the rendering. One of the first features I worked on was the connect function:
import { connect } from 'stent/lib/helpers';
Machine.create('MachineA', ...);
Machine.create('MachineB', ...);
connect()
.with('MachineA', 'MachineB')
.map((MachineA, MachineB) => {
... rendering here
});
We say which machines are important to us and give their names. The callback that we pass to map is fired once initially and then later every time the state of some of the machines changes. This is where we trigger the rendering. At this point, we have direct access to the connected machines, so we can retrieve the current state and methods. There are also mapOnce, for getting the callback fired only once, and mapSilent, to skip that initial execution.
For convenience, a helper is exported specifically for React integration. It is really similar to Redux’s connect(mapStateToProps).
import React from 'react';
import { connect } from 'stent/lib/react';
class TodoList extends React.Component {
render() {
const { isIdle, todos } = this.props;
...
}
}
// MachineA and MachineB are machines defined
// using Machine.create function
export default connect(TodoList)
.with('MachineA', 'MachineB')
.map((MachineA, MachineB) => {
isIdle: MachineA.isIdle,
todos: MachineB.state.todos
});
Stent runs our mapping callback and expects to receive an object — an object that is sent as props to our React component.
What Is State In The Context Of Stent?
Until now, our state has been simple strings. Unfortunately, in the real world, we have to keep more than a string in state. This is why Stent’s state is actually an object with properties inside. The only one reserved property is name. Everything else is app-specific data. For example:
{ name: 'idle' }
{ name: 'fetching', todos: [] }
{ name: 'forward', speed: 120, gear: 4 }
My experience with Stent so far shows me that if the state object becomes larger, we’d probably need another machine that handles those additional properties. Identifying the various states takes some time, but I believe this is a big step forward in writing more manageable applications. It is a little bit like predicting the future and drawing frames of the possible actions.
Working With The State Machine
Similar to the example in the beginning, we have to define the possible (finite) states of our machine and describe the possible inputs:
import { Machine } from 'stent';
const machine = Machine.create('sprinter', {
state: { name: 'idle' }, // initial state
transitions: {
'idle': {
'run please': function () {
return { name: 'running' };
}
},
'running': {
'stop now': function () {
return { name: 'idle' };
}
}
}
});
We have our initial state, idle, which accepts an action of run. Once the machine is in a running state, we are able to fire the stop action, which brings us back to the idle state.
You’ll probably remember the dispatch and changeStateTo helpers from our implementation earlier. This library provides the same logic, but it is hidden internally, and we don’t have to think about it. For convenience, based on the transitions property, Stent generates the following:
- helper methods for checking whether the machine is in a particular state — the
idlestate produces theisIdle()method, whereas forrunningwe haveisRunning(); - helper methods for dispatching actions:
runPlease()andstopNow().
So, in the example above, we can use this:
machine.isIdle(); // boolean
machine.isRunning(); // boolean
machine.runPlease(); // fires action
machine.stopNow(); // fires action
Combining the automatically generated methods with the connect utility function, we are able to close the circle. A user interaction triggers the machine input and action, which updates the state. Because of that update, the mapping function passed to connect gets fired, and we are informed about the state change. Then, we rerender.
Input And Action Handlers
Probably the most important bit is the action handlers. This is the place where we write most of the application logic because we are responding to input and changed states. Something I really like in Redux is also integrated here: the immutability and simplicity of the reducer function. The essence of Stent’s action handler is the same. It receives the current state and action payload, and it must return the new state. If the handler returns nothing (undefined), then the state of the machine stays the same.
transitions: {
'fetching': {
'success': function (state, payload) {
const todos = [ ...state.todos, payload ];
return { name: 'idle', todos };
}
}
}
Let’s assume we need to fetch data from a remote server. We fire the request and transition the machine to a fetching state. Once the data comes from the back end, we fire a success action, like so:
machine.success({ label: '...' });
Then, we go back to an idle state and keep some data in the form of the todos array. There are a couple of other possible values to set as action handlers. The first and the simplest case is when we pass just a string that becomes the new state.
transitions: {
'idle': {
'run': 'running'
}
}
This is a transition from { name: 'idle' } to { name: 'running' } using the run() action. This approach is useful when we have synchronous state transitions and don’t have any meta data. So, if we keep something else in state, that type of transition will flush it out. Similarly, we can pass a state object directly:
transitions: {
'editing': {
'delete all todos': { name: 'idle', todos: [] }
}
}
We are transitioning from editing to idle using the deleteAllTodos action.
We already saw the function handler, and the last variant of the action handler is a generator function. It is inspired by the Redux-Saga project, and it looks like this:
import { call } from 'stent/lib/helpers';
Machine.create('app', {
'idle': {
'fetch data': function * (state, payload) {
yield { name: 'fetching' }
try {
const data = yield call(requestToBackend, '/api/todos/', 'POST');
return { name: 'idle', data };
} catch (error) {
return { name: 'error', error };
}
}
}
});
If you don’t have experience with generators, this might look a bit cryptic. But the generators in JavaScript are a powerful tool. We are allowed to pause our action handler, change state multiple times and handle async logic.
Fun With Generators
When I was first introduced to Redux-Saga, I thought it was an over-complicated way to handle async operations. In fact, it is a pretty smart implementation of the command design pattern. The main benefit of this pattern is that it separates the invocation of logic and its actual implementation.
In other words, we say what we want but not how it should happen. Matt Hink’s blog series helped me understand how sagas are implemented, and I strongly recommend reading it. I brought the same ideas into Stent, and for the purpose of this article, we will say that by yielding stuff, we are giving instructions about what we want without actually doing it. Once the action is performed, we receive the control back.
At the moment, a couple of things may be sent out (yielded):
- a state object (or a string) for changing the state of the machine;
- a call of the
callhelper (it accepts a synchronous function, which is a function that returns a promise or another generator function) — we are basically saying, “Run this for me, and if it is asynchronous, wait. Once you are done, give me the result.”; - a call of the
waithelper (it accepts a string representing another action); if we use this utility function, we pause the handler and wait for another action to be dispatched.
Here is a function that illustrates the variants:
const fireHTTPRequest = function () {
return new Promise((resolve, reject) => {
// ...
});
}
...
transitions: {
'idle': {
'fetch data': function * () {
yield 'fetching'; // sets the state to { name: 'fetching' }
yield { name: 'fetching' }; // same as above
// wait for getTheData and checkForErrors actions
// to be dispatched
const [ data, isError ] = yield wait('get the data', 'check for errors');
// wait for the promise returned by fireHTTPRequest
// to be resolved
const result = yield call(fireHTTPRequest, '/api/data/users');
return { name: 'finish', users: result };
}
}
}
As we can see, the code looks synchronous, but in fact it is not. It is just Stent doing the boring part of waiting for the resolved promise or iterating over another generator.
How Stent Is Solving My Redux Concerns
Too Much Boilerplate Code
The Redux (and Flux) architecture relies on actions that circulate in our system. When the application grows, we usually end up having a lot of constants and action creators. These two things are very often in different folders, and tracking the code’s execution sometimes takes time. Also, when adding a new feature, we always have to deal with a whole set of actions, which means defining more action names and action creators.
In Stent, we don’t have action names, and the library creates the action creators automatically for us:
const machine = Machine.create('todo-app', {
state: { name: 'idle', todos: [] },
transitions: {
'idle': {
'add todo': function (state, todo) {
...
}
}
}
});
machine.addTodo({ title: 'Fix that bug' });
We have the machine.addTodo action creator defined directly as a method of the machine. This approach also solved another problem that I faced: finding the reducer that responds to a particular action. Usually, in React components, we see action creator names such as addTodo; however, in the reducers, we work with a type of action that is constant. Sometimes I have to jump to the action creator code just so that I can see the exact type. Here, we have no types at all.
Unpredictable State Changes
In general, Redux does a good job of managing state in an immutable fashion. The problem is not in Redux itself, but in that the developer is allowed to dispatched any action at any time. If we say that we have an action that turns the lights on, is it OK to fire that action twice in a row? If not, then how we are supposed to solve this issue with Redux? Well, we would probably put some code in the reducer that protects the logic and that check whether the lights are already turned on — maybe an if clause that checks the current state. Now the question is, isn’t this beyond the scope of the reducer? Should the reducer know about such edge cases?
What I’m missing in Redux is a way to stop the dispatching of an action based on the application’s current state without polluting the reducer with conditional logic. And I don’t want to take this decision to the view layer either, where the action creator is fired. With Stent, this happens automatically because the machine does not respond to actions that are not declared in the current state. For example:
const machine = Machine.create('app', {
state: { name: 'idle' },
transitions: {
'idle': {
'run': 'running',
'jump': 'jumping'
},
'running': {
'stop': 'idle'
}
}
});
// this is fine
machine.run();
// This will do nothing because at this point
// the machine is in a 'running' state and there is
// only 'stop' action there.
machine.jump();
The fact that the machine accepts only specific inputs at a given time protects us from weird bugs and makes our applications more predictable.
States, Not Transitions
Redux, like Flux, makes us think in terms of transitions. The mental model of developing with Redux is pretty much driven by actions and how these actions transform the state in our reducers. That is not bad, but I’ve found it makes more sense to think in terms of states instead — what states the app might be in and how these states represent the business requirements.
Conclusion
The concept of state machines in programming, especially in UI development, was eye-opening for me. I started seeing state machines everywhere, and I have some desire to always shift to that paradigm. I definitely see the benefits of having more strictly defined states and transitions between them. I’m always searching for ways to make my apps simple and readable. I believe that state machines are a step in this direction. The concept is simple and at the same time powerful. It has the potential to eliminate a lot of bugs.