



In Part 1 we looked at how APIs have evolved over the last few decades and how each one gave way to the next. We also talked about some of the particular drawbacks of using REST for mobile client development. In this article, I want to look at where mobile client API design appears to be headed — with a particular emphasis on GraphQL.
There are, of course, lots of people, companies, and projects that have tried to address RESTs shortcomings over the years: HAL, Swagger/OpenAPI, OData JSON API and dozens of other smaller or internal projects have all sought to bring order to the spec-less world of REST. Rather than take the world for what it is and propose incremental improvements, or to try to assemble enough disparate pieces to make REST into what I need, I’d like to try a thought experiment. Given an understanding of the techniques that have and have not worked in the past, I’d like to take today’s constraints and our immensely more expressive languages to try and sketch out the API that we want. Let’s work from the developer experience backward rather than the implementation forwards (I’m looking at you SQL).
Minimal HTTP Traffic
We know the cost of every (HTTP/1) network request is high on quite a few measures from latency to battery life. Ideally, clients of our new API will need a way to ask for all of the data that they need in as few round-trips as possible.
Minimal Payloads
We also know that the average client is resource constrained, in bandwidth, CPU, and memory, so our goal should be to send only the information our client needs. To do this, we will probably need a way for the client to ask for specific pieces of data.
Human Readable
We learned from the SOAP days that an API isn’t easy to interact with, people will grimace at its mention. Engineering teams want to use the same tools that we’ve relied on for years like curl, wget and Charles and the network tab of our browsers.
Tooling Rich
Another thing that we learned from XML-RPC and SOAP is that client/server contracts and type systems, in particular, are amazingly useful. If at all possible, any new API would have the lightness of a format like JSON or YAML with the introspection capability of more structured and type-safe contracts.
Preservation of Local Reasoning
Over the years, we’ve come to agree on some guiding principles in how to organize large codebases - the main one being “separation of concerns.” Unfortunately for most projects, this tends to break down in the form of a centralized data access layer. If possible, different parts of an application should have the option to manage its own data needs along with its other functionality.
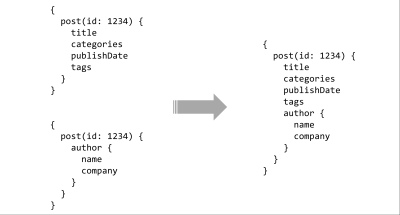
Since we’re designing a client-centric API, let’s start with what it might it look like to fetch data in an API like this. If we know that we need to both make minimal round trips and that we need to be able to filter out fields we don’t want, we need a way to both traverse large sets of data and to only request the parts of it that are useful to us. A query language seems like it would fit well here.
We don’t need to ask questions of our data in the same way that you do with a database, so an imperative language like SQL seems like the wrong tool. In fact, our primary goals are to traverse pre-existing relationships and limit fields which we should be able to do with something relatively simple and declarative. The industry has pretty well settled on JSON for non-binary data so let’s start with a JSON-like declarative query language. We should be able to describe the data we need, and the server should return JSON containing those fields.

{kind=link}
A declarative query language fulfills the requirement for both minimal payloads and minimal HTTP traffic, but there is another benefit that will help us with another of our design goals. Many declarative languages, query and otherwise, can be efficiently manipulated as if they were data. If we design carefully, our query language will allow developers to break large requests apart and recombine them in any way that made sense to their project. Using a query language like this would help us move towards our ultimate goal of Preservation of Local Reasoning.
There are a lot of exciting things you can do once your queries become “data.” For example, you could intercept all requests and batch them similar to how a Virtual DOM batches DOM updates, you could also use a compiler to extract the small queries at build-time to pre-cache the data or you could build a sophisticated cache system like Apollo Cache.
{kind=link}
The final item on the API wish list is tooling. We already get some of this by using a query language, but the real power comes when you pair it with a type system. With a simple typed schema on the server, there are nearly endless possibilities for rich tooling. Queries can be statically analyzed and validated against the contract, IDE integrations can provide hints or auto-completion, compilers can make build-time optimizations to queries, or multiple schemas can be stitched together to form a contiguous API surface.

{kind=link}
Designing an API that pairs a query language and a type system may sound like a dramatic proposal but people have been experimenting with this, in various forms, for years. XML-RPC pushed for typed responses in the mid-90s and its successor, SOAP, dominated for years! More recently, there are things like Meteor’s MongoDB abstraction, RethinkDB’s (RIP) Horizon, Netflix’s amazing Falcor which they’ve been using for Netflix.com for years and last there is Facebook’s GraphQL. For the rest of this essay, I will be focused on GraphQL since, while other projects like Falcor are doing similar things, the community mindshare seems to favor it overwhelmingly.
What Is GraphQL?
First, I have to say that I lied a little bit. The API we constructed above was GraphQL. GraphQL is just a type system for your data, a query language for traversing it - the rest is just detail. In GraphQL, you describe your data as a graph of interconnections, and your client asks specifically for the subset of the data that it needs. There is a lot of speaking and writing about all of the incredible things that GraphQL enables, but the core concepts are very manageable and uncomplicated.
To make these concepts more concrete, and to help illustrate how GraphQL tries to address some of the problems in Part 1, the rest of this post will build a GraphQL API that can power the blog in Part 1 of this series. Before jumping into the code, there are a few things about GraphQL to keep in mind.
GraphQL Is A Spec (Not An Implementation)
GraphQL is only a spec. It defines a type system along with a simple query language, and that’s it. The first thing that falls out of this is that GraphQL not, in any way, tied to a particular language. There are over two dozen implementations in everything from Haskell to C++ of which JavaScript is only one. Shortly after the spec was announced, Facebook released a reference implementation in JavaScript but, since they don’t use it internally, implementations in languages like Go and Clojure can be even better or faster.
GraphQL’s Spec Doesn’t Mention Clients Or Data
If you read the spec, you’ll notice that two things are conspicuously absent. First, beyond the query language, there is no mention of client integrations. Tools like Apollo, Relay, Loka and the like are possible because of GraphQL’s design, but they are in no way a part of or required for using it. Second, there is no mention of any particular data-layer. The same GraphQL server can, and frequently does, fetch data from a heterogeneous set of sources. It can request cached data from Redis, do an address lookup from the USPS API and call protobuff based microservices and the client would never know the difference.
Progressive Disclosure Of Complexity
GraphQL has, to many people, has hit a rare intersection of power and simplicity. It does a fantastic job of making the simple things simple and the hard things possible. Getting a server running and serving typed data over HTTP can be just a few lines of code in just about any language you can imagine.
For example, a GraphQL server can wrap an existing REST API, and its clients can get data with regular GET requests just as you would interact with other services. You can see a demo here. Or, if the project needs a more sophisticated set of tools, it is possible to use GraphQL to do things like field level authentication, pub/sub subscriptions or pre-compiled/cached queries.
An Example App
The goal of this example is to demonstrate the power and simplicity of GraphQL in ~70 lines of JavaScript, not to write an extensive tutorial. I won’t go into too much detail about the syntax and semantics but all of the code here is runnable, and there is a link to a downloadable version of the project at the end of the article. If after going through this, you’d like to dig a little deeper, I have a collection of resources on my blog that will help you build bigger more robust services.
For the demo, I will be using JavaScript, but the steps are very similar in any language. Let’s start with some sample data using the amazing Mocky.io.
{
9: {
id: 9,
name: "Eric Baer",
company: "Formidable"
},
...
}[
{
id: 17,
author: "author/7",
categories: [
"software engineering"
],
publishdate: "2016/03/27 14:00",
summary: "...",
tags: [
"http/2",
"interlock"
],
title: "http/2 server push"
},
...
]
The first step is to create a new project with express and the express-graphql middleware.
bash
npm init -y && npm install --save graphql express express-graphqlAnd to create an index.js file with an express server.
const app = require("express")();
const PORT = 5000;
app.listen(PORT, () => {
console.log(`Server running at http://localhost:${PORT}`);
});To start working with GraphQL, we can start by modeling the data in the REST API. In a new file called schema.js add the following:
const {
GraphQLInt,
GraphQLList,
GraphQLObjectType,
GraphQLSchema,
GraphQLString
} = require("graphql");
const Author = new GraphQLObjectType({
name: "Author",
fields: {
id: { type: GraphQLInt },
name: { type: GraphQLString },
company: { type: GraphQLString },
}
});
const Post = new GraphQLObjectType({
name: "Post",
fields: {
id: { type: GraphQLInt },
author: { type: Author },
categories: { type: new GraphQLList(GraphQLString) },
publishDate: { type: GraphQLString },
summary: { type: GraphQLString },
tags: { type: new GraphQLList(GraphQLString) },
title: { type: GraphQLString }
}
});
const Blog = new GraphQLObjectType({
name: "Blog",
fields: {
posts: { type: new GraphQLList(Post) }
}
});
module.exports = new GraphQLSchema({
query: Blog
});The code above maps the types in our API’s JSON responses to GraphQL’s types. A GraphQLObjectType corresponds to a JavaScript Object, a GraphQLString corresponds to a JavaScript String and so on. The one special type to pay attention to is the GraphQLSchema on the last few lines. The GraphQLSchema is the root-level export of a GraphQL — the starting point for queries to traverse the graph. In this basic example, we are only defining the query; this is where you would define mutations (writes) and subscriptions.
Next, we are going to add the schema to our express server in the index.js file. To do this, we will add the express-graphql middleware and pass it the schema.
const graphqlHttp = require("express-graphql");
const schema = require("./schema.js");
const app = require("express")();
const PORT = 5000;
app.use(graphqlHttp({
schema,
// Pretty Print the JSON response
pretty: true,
// Enable the GraphiQL dev tool
graphiql: true
}));
app.listen(PORT, () => {
console.log(`Server running at http://localhost:${PORT}`);
});At this point, although we’re not returning any data, we have a working GraphQL server that provides its schema to clients. To make starting the application easier we will also add a start script to the package.json.
"scripts": {
"start": "nodemon index.js"
},Running the project and going to http://localhost:5000/ should show a data explorer called GraphiQL. GraphiQL will load by default so long as the HTTP Accept header is not set to application/json. Calling this same URL with fetch or cURL using application/json will return a JSON result. Feel free to play around with the built-in documentation and writing a query.
{kind=link}
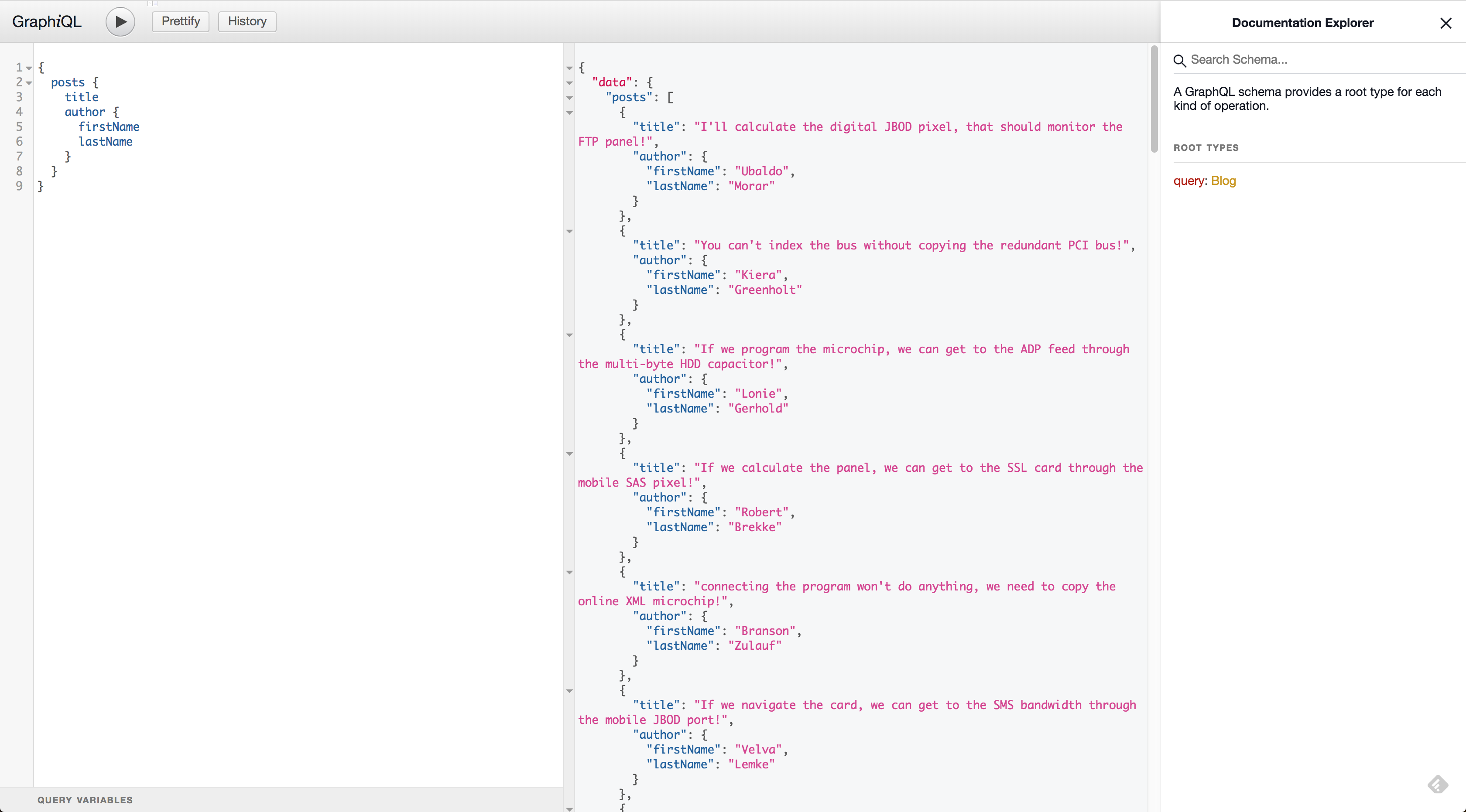
The only thing left to do to complete the server is to wire the underlying data into the schema. To do this, we need to define resolve functions. In GraphQL, a query is run from the top down calling a resolve function as it traverses the tree. For example, for the following query:
query homepage {
posts {
title
}
}GraphQL will first call posts.resolve(parentData) then posts.title.resolve(parentData). Let’s start by defining the resolver on our list of blog posts.
const Blog = new GraphQLObjectType({
name: "Blog",
fields: {
posts: {
type: new GraphQLList(Post),
resolve: () => {
return fetch('http://www.mocky.io/v2/594a3ac810000053021aa3a7')
.then((response) => response.json())
}
}
}
});I am using the isomorphic-fetch package here to make HTTP request since it nicely demonstrates how to return a Promise from a resolver, but you can use anything you like. This function will return an array of Posts to the Blog type. The default resolve function for the JavaScript implementation of GraphQL is parentData.<fieldName>. For example, the default resolver for the Author’s name field would be:
rawAuthorObject => rawAuthorObject.nameThis single override resolver should provide the data for the entire post object. We still need to define the resolver for Author but if you run a query to fetch the data needed for the homepage you should see it working.

{kind=link}
Since the author attribute in our posts API is just the author ID, when GraphQL looks for an Object that defines name and company and finds a String, it will just return null. To wire in the Author, we need to change our Post schema to look like the following:
const Post = new GraphQLObjectType({
name: "Post",
fields: {
id: { type: GraphQLInt },
author: {
type: Author,
resolve: (subTree) => {
// Get the AuthorId from the post data
const authorId = subTree.author.split("/")[1];
return fetch('http://www.mocky.io/v2/594a3bd21000006d021aa3ac')
.then((response) => response.json())
.then(authors => authors[authorId]);
}
},
...
}
});Now, we have a fully working GraphQL server that wraps a REST API. The full source can be downloaded from this Github link, or run from this GraphQL launchpad.
You may be wondering about the tooling you’ll need to use to consume a GraphQL endpoint like this. There are a lot of options like Relay and Apollo but to start out, I think that the simple approach is the best. If you played around with GraphiQL much, you might have noticed that it has a long URL. This URL is just a URI encoded version of your query. To build a GraphQL query in JavaScript, you can do something like this:
const homepageQuery = `
posts {
title
author {
name
}
}
`;
const uriEncodedQuery = encodeURIComponent(homepageQuery);
fetch(`http://localhost:5000/?query=${uriEncodedQuery}`);Or, if you’d like, you can copy paste the URL right from GraphiQL like this:
http://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageSince we have a GraphQL endpoint and a way to use it, we can compare it to our RESTish API. The code we needed to write to fetch our data using a RESTish API looked like this:
Using A RESTish API
const getPosts = () => fetch(`${API_ROOT}/posts`);
const getPost = postId => fetch(`${API_ROOT}/post/${postId}`);
const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`);
const getPostWithAuthor = post => {
return getAuthor(post.author)
.then(author => {
return Object.assign({}, post, { author })
})
};
const getHomePageData = () => {
return getPosts()
.then(posts => {
const postDetails = posts.map(getPostWithAuthor);
return Promise.all(postDetails);
})
};Using A GraphQL API
const homepageQuery = `
posts {
title
author {
name
}
}
`;
const uriEncodedQuery = encodeURIComponent(homepageQuery);
fetch(`http://localhost:5000/?query=${uriEncodedQuery}`);In summary, we’ve used GraphQL to:
- Reduce nine requests (list of posts, four blog posts and the author of each post).
- Reduce the amount of data sent by a significant percentage.
- Use incredible developer tools to build our queries.
- Write much cleaner code in our client.
Flaws In GraphQL
While I believe the hype is justified, there is no silver bullet, and as great as GraphQL is, it is not without flaws.
Data Integrity
GraphQL sometimes seems like a tool that was purpose-built for good data. It often works best as a sort of gateway, stitching together disparate services or highly normalized tables. If the data that comes back from the services you consume is messy and unstructured, adding a data transformation pipeline underneath GraphQL can be a real challenge. The scope of a GraphQL resolve function is only its own data and that of its children. If an orchestration task needs access to data in a sibling or parent in the tree it can be especially challenging.
Complex Error Handling
A GraphQL request can run an arbitrary number of queries, and each query can hit an arbitrary number of services. If any part of the request fails, rather than fail the entire request, GraphQL, by default, returns partial data. Partial data is likely the right choice technically, and it can be incredibly useful and efficient. The drawback is that error handling is no longer as simple as checking for HTTP status code. This behavior can be turned off, but more often than not, clients end up with more sophisticated error cases.
Caching
Though it is often a good idea to use static GraphQL queries, for organizations like Github that allow arbitrary queries, network caching with standard tools like Varnish or Fastly will no longer be possible.
High CPU Cost
Parsing, validating and type-checking a query is a CPU bound process which can lead to performance problems in single-threaded languages like JavaScript.
This is only a problem for runtime query evaluation.
Closing Thoughts
GraphQL’s features are not a revolution — some of them have been around for nearly 30 years. What makes GraphQL powerful is that the level of polish, integration, and ease-of-use make it more than the sum of its parts.
Many of the things GraphQL accomplishes can, with effort and discipline, be achieved using REST or RPC, but GraphQL brings state of the art APIs to the enormous number of projects that may not have the time, resources or tools to do this themselves. It’s also true that GraphQL is not a silver bullet, but its flaws tend to be minor and well understood. As somebody who has built up a reasonably complicated GraphQL server, I can easily say that the benefits easily outweigh the cost.
This essay is focused almost entirely on why GraphQL exists and the problems it solves. If this has piqued your interest in learning more about its semantics and how to use it, I encourage you to learn in whatever way works best for you whether it’s blogs, youtube or just reading the source (How To GraphQL is particularly good).
If you enjoyed this article (or if you hated it) and would like to give me feedback, please find me on Twitter as @ebaerbaerbaer or LinkedIn at ericjbaer.