



Nowadays, with any Web app you build, you have dozens of architectural decisions to make. And you want to make the right ones: You want to use technologies that allow for rapid development, constant iteration, maximal efficiency, speed, robustness and more. You want to be lean and you want to be agile. You want to use technologies that will help you succeed in the short and long term. And those technologies are not always easy to pick out.
In my experience, full-stack JavaScript hits all the marks. You’ve probably seen it around; perhaps you’ve considered its usefulness and even debated it with friends. But have you tried it yourself? In this post, I’ll give you an overview of why full-stack JavaScript might be right for you and how it works its magic.
Further Reading on SmashingMag:
- A Thorough Introduction To Backbone.Marionette (Part 1)
- Journey Through The JavaScript MVC Jungle
- A Detailed Introduction To Webpack
- Get Up And Running With Grunt
To give you a quick preview:
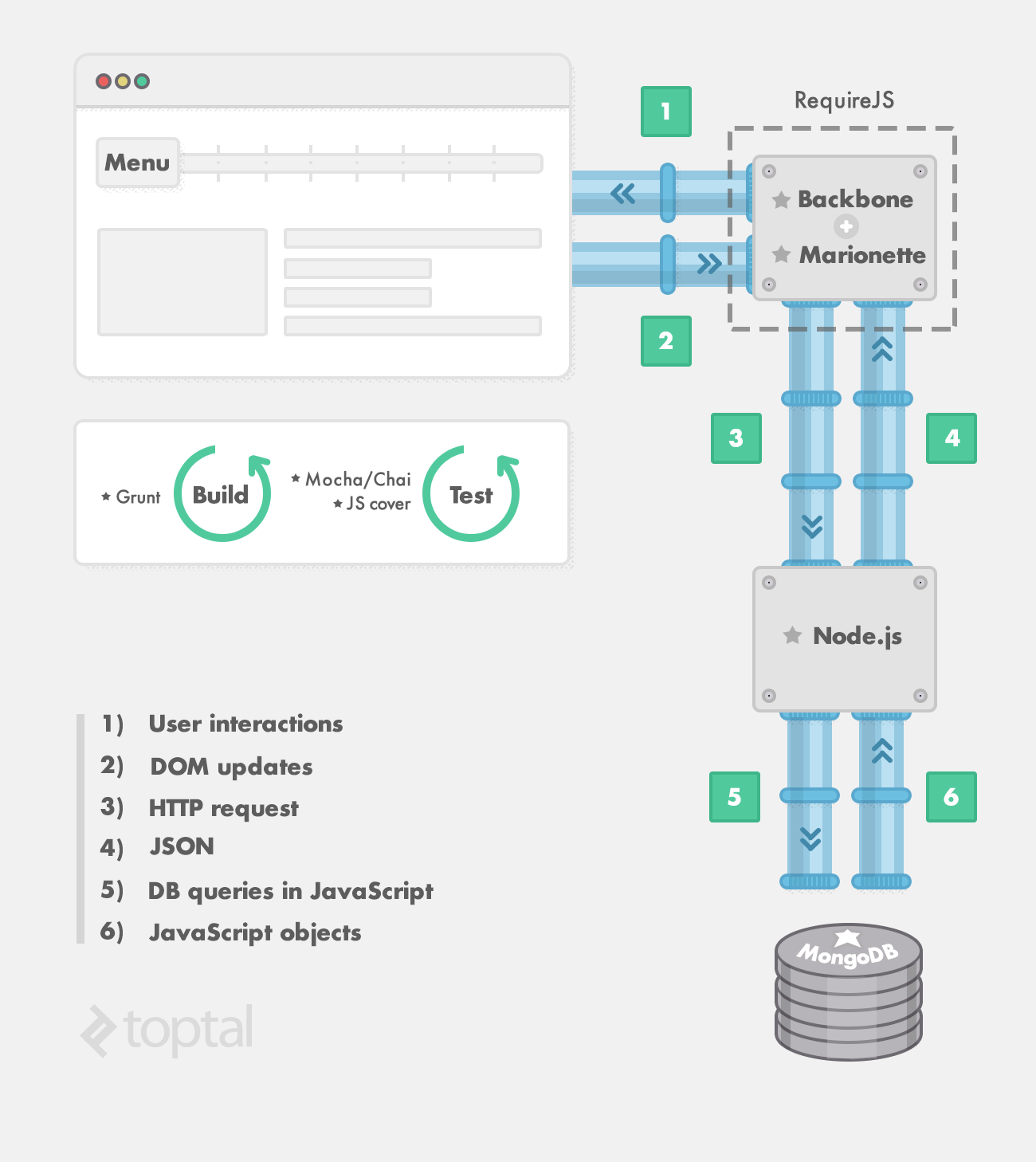
I’ll introduce these components piece by piece. But first, a short note on how we got to where we are today.
Why I Use JavaScript
I’ve been a Web developer since 1998. Back then, we used Perl for most of our server-side development; but even since then, we’ve had JavaScript on the client side. Web server technologies have changed immensely since then: We went through wave after wave of languages and technologies, such as PHP, ASP, JSP, .NET, Ruby, Python, just to name a few. Developers began to realize that using two different languages for the client and server environments complicates things.
In the early era of PHP and ASP, when template engines were just an idea, developers embedded application code in their HTML. Seeing embedded scripts like this was not uncommon:
<script>
<?php
if ($login == true){
?>
alert("Welcome");
<?php
}
?>
</script>
Or, even worse:
<script>
var users_deleted = [];
<?php
$arr_ids = array(1,2,3,4);
foreach($arr_ids as $value){
?>
users_deleted.push("<php>");
<?php
}
?>
</script>
For starters, there were the typical errors and confusing statements between languages, such as for and foreach. Furthermore, writing code like this on the server and on the client to handle the same data structure is uncomfortable even today (unless, of course, you have a development team with engineers dedicated to the front end and engineers for the back end — but even if they can share information, they wouldn’t be able to collaborate on each other’s code):
<?php
$arr = array("apples", "bananas", "oranges", "strawberries"),
$obj = array();
$i = 10;
foreach($arr as $fruit){
$obj[$fruit] = $i;
$i += 10;
}
echo json_encode(obj);
?>
<script>
$.ajax({
url:"/json.php",
success: function(data){
var x;
for(x in data){
alert("fruit:" + x + " points:" + data[x]);
}
}
});
</script>
The initial attempts to unify under a single language were to create client components on the server and compile them to JavaScript. This didn’t work as expected, and most of those projects failed (for example, ASP MVC replacing ASP.NET Web forms, and GWT arguably being replaced in the near future by Polymer). But the idea was great, in essence: a single language on the client and the server, enabling us to reuse components and resources (and this is the keyword: resources).
The answer was simple: Put JavaScript on the server.
JavaScript was actually born server-side in Netscape Enterprise Server, but the language simply wasn’t ready at the time. After years of trial and error, Node.js finally emerged, which not only put JavaScript on the server, but also promoted the idea of non-blocking programming, bringing it from the world of nginx, thanks to the Node creator’s nginx background, and (wisely) keeping it simple, thanks to JavaScript’s event-loop nature.
(In a sentence, non-blocking programming aims to put time-consuming tasks off to the side, usually by specifying what should be done when these tasks are completed, and allowing the processor to handle other requests in the meantime.)
Node.js changed the way we handle I/O access forever. As Web developers, we were used to the following lines when accessing databases (I/O):
var resultset = db.query("SELECT * FROM 'table'");
drawTable(resultset);
This line essentially blocks your code, because your program stops running until your database driver has a resultset to return. In the meantime, your platform’s infrastructure provides the means for concurrency, usually using threads and forks.
With Node.js and non-blocking programming, we’re given more control over program flow. Now (even if you still have parallel execution hidden by your database (I/O) driver), you can define what the program should do in the meantime and what it will do when you receive the resultset:
db.query("SELECT * FROM 'table'", function(resultset){
drawTable(resultset);
});
doSomeThingElse();
With this snippet, we’ve defined two program flows: The first handles our actions just after sending the database query, while the second handles our actions just after we receive our resultSet using a simple callback. This is an elegant and powerful way to manage concurrency. As they say, “Everything runs in parallel — except your code.” Thus, your code will be easy to write, read, understand and maintain, all without your losing control over program flow.
These ideas weren’t new at the time — so, why did they become so popular with Node.js? Simple: Non-blocking programming can be achieved in several ways. Perhaps the easiest is to use callbacks and an event loop. In most languages, that’s not an easy task: While callbacks are a common feature in some other languages, an event loop is not, and you’ll often find yourself grappling with external libraries (for example, Python with Tornado).
But in JavaScript, callbacks are built into the language, as is the event loop, and almost every programmer who has even dabbled in JavaScript is familiar with them (or at least has used them, even if they don’t quite understand what the event loop is). Suddenly, every startup on Earth could reuse developers (i.e. resources) on both the client and server side, solving the “Python Guru Needed” job posting problem.
So, now we have an incredibly fast platform (thanks to non-blocking programming), with a programming language that’s incredibly easy to use (thanks to JavaScript). But is it enough? Will it last? I’m sure JavaScript will have an important place in the future. Let me tell you why.
Functional Programming
JavaScript was the first programming language to bring the functional paradigm to the masses (of course, Lisp came first, but most programmers have never built a production-ready application using it). Lisp and Self, Javascript’s main influences, are full of innovative ideas that can free our minds to explore new techniques, patterns and paradigms. And they all carry over to JavaScript. Take a look at monads, Church numbers or even (for a more practical example) Underscore’s collections functions, which can save you lines and lines of code.
Dynamic Objects and Prototypal Inheritance
Object-oriented programming without classes (and without endless hierarchies of classes) allows for fast development — just create objects, add methods and use them. More importantly, it reduces refactoring time during maintenance tasks by enabling the programmer to modify instances of objects, instead of classes. This speed and flexibility pave the way for rapid development.
JavaScript Is the Internet
JavaScript was designed for the Internet. It’s been here since the beginning, and it’s not going away. All attempts to destroy it have failed; recall, for instance, the downfall of Java Applets, VBScript’s replacement by Microsoft’s TypeScript (which compiles to JavaScript), and Flash’s demise at the hands of the mobile market and HTML5. Replacing JavaScript without breaking millions of Web pages is impossible, so our goal going forward should be to improve it. And no one is better suited for the job than Technical Committee 39 of ECMA.
Sure, alternatives to JavaScript are born every day, like CoffeeScript, TypeScript and the millions of languages that compile to JavaScript. These alternatives might be useful for development stages (via source maps), but they will fail to supplant JavaScript in the long run for two reasons: Their communities will never be bigger, and their best features will be adopted by ECMAScript (i.e. JavaScript). JavaScript is not an assembly language: It’s a high-level programming language with source code that you can understand — so, you should understand it.
End-to-End JavaScript: Node.js And MongoDB
We’ve covered the reasons to use JavaScript. Next, we’ll look at JavaScript as a reason to use Node.js and MongoDB.
Node.js
Node.js is a platform for building fast and scalable network applications — that’s pretty much what the Node.js website says. But Node.js is more than that: It’s the hottest JavaScript runtime environment around right now, used by a ton of applications and libraries — even browser libraries are now running on Node.js. More importantly, this fast server-side execution allows developers to focus on more complex problems, such as Natural for natural language processing. Even if you don’t plan to write your main server application with Node.js, you can use tools built on top of Node.js to improve your development process; for example, Bower for front-end package management, Mocha for unit testing, Grunt for automated build tasks and even Brackets for full-text code editing.
So, if you’re going to write JavaScript applications for the server or the client, you should become familiar with Node.js, because you will need it daily. Some interesting alternatives exist, but none have even 10% of Node.js’ community.
MongoDB
MongoDB is a NoSQL document-based database that uses JavaScript as its query language (but is not written in JavaScript), thus completing our end-to-end JavaScript platform. But that’s not even the main reason to choose this database.
MongoDB is schema-less, enabling you to persist objects in a flexible way and, thus, adapt quickly to changes in requirements. Plus, it’s highly scalable and based on map-reduce, making it suitable for big data applications. MongoDB is so flexible that it can be used as a schema-less document database, a relational data store (although it lacks transactions, which can only be emulated) and even as a key-value store for caching responses, like Memcached and Redis.
Server Componentization With Express
Server-side componentization is never easy. But with Express (and Connect) came the idea of “middleware.” In my opinion, middleware is the best way to define components on the server. If you want to compare it to a known pattern, it’s pretty close to pipes and filters.
The basic idea is that your component is part of a pipeline. The pipeline processes a request (i.e. the input) and generates a response (i.e. the output), but your component isn’t responsible for the entire response. Instead, it modifies only what it needs to and then delegates to the next piece in the pipeline. When the last piece of the pipeline finishes processing, the response is sent back to the client.
We refer to these pieces of the pipeline as middleware. Clearly, we can create two kinds of middleware:
- Intermediates. An intermediate processes the request and the response but is not fully responsible for the response itself and so delegates to the next middleware.
- Finals. A final has full responsibility over the final response. It processes and modifies the request and the response but doesn’t need to delegate to the next middleware. In practice, delegating to the next middleware anyway will allow for architectural flexibility (i.e. for adding more middleware later), even if that middleware doesn’t exist (in which case, the response would go straight to the client).

As a concrete example, consider a “user manager” component on the server. In terms of middleware, we’d have both finals and intermediates. For our finals, we’d have such features as creating a user and listing users. But before we can perform those actions, we need our intermediates for authentication (because we don’t want unauthenticated requests coming in and creating users). Once we’ve created these authentication intermediates, we can just plug them in anywhere that we want to turn a previously unauthenticated feature into an authenticated feature.
Single-Page Applications
When working with full-stack JavaScript, you’ll often focus on creating single-page applications (SPAs). Most Web developers are tempted more than once to try their hand at SPAs. I’ve built several (mostly proprietary), and I believe that they are simply the future of Web applications. Have you ever compared an SPA to a regular Web app on a mobile connection? The difference in responsiveness is in the order of tens of seconds.
(Note: Others might disagree with me. Twitter, for example, rolled back its SPA approach. Meanwhile, large websites such as Zendesk are moving towards it. I’ve seen enough evidence of the benefits of SPAs to believe in them, but experiences vary.)
If SPAs are so great, why build your product in a legacy form? A common argument I hear is that people are worried about SEO. But if you handle things correctly, this shouldn’t be an issue: You can take different approaches, from using a headless browser (such as PhantomJS) to render the HTML when a Web crawler is detected to performing server-side rendering with the help of existing frameworks.
Client Side MV* With Backbone.js, Marionette And Twitter Bootstrap
Much has been said about MV* frameworks for SPAs. It’s a tough choice, but I’d say that the top three are Backbone.js, Ember and AngularJS.
All three are very well regarded. But which is best for you?
Unfortunately, I must admit that I have limited experience with AngularJS, so I’ll leave it out of the discussion. Now, Ember and Backbone.js represent two different ways of attacking the same problem.
Backbone.js is minimal and offers just enough for you to create a simple SPA. Ember, on the other hand, is a complete and professional framework for creating SPAs. It has more bells and whistles, but also a steeper learning curve. (You can read more about Ember.js here.)
Depending on the size of your application, the decision could be as easy as looking at the “features used” to “features available” ratio, which will give you a big hint.
Styling is a challenge as well, but again, we can count on frameworks to bail us out. For CSS, Twitter Bootstrap is a good choice because it offers a complete set of styles that are both ready to use out of the box and easy to customize.
Bootstrap was created in the LESS language, and it’s open source, so we can modify it if need be. It comes with a ton of UX controls that are well documented. Plus, a customization model enables you to create your own. It is definitely the right tool for the job.
Best Practices: Grunt, Mocha, Chai, RequireJS and CoverJS
Finally, we should define some best practices, as well as mention how to implement and maintain them. Typically, my solution centers on several tools, which themselves are based on Node.js.
Mocha and Chai
These tools enable you to improve your development process by applying test-driven development (TDD) or behavior-driven development (BDD), creating the infrastructure to organize your unit tests and a runner to automatically run them.
Plenty of unit test frameworks exist for JavaScript. Why use Mocha? The short answer is that it’s flexible and complete.
The long answer is that it has two important features (interfaces and reporters) and one significant absence (assertions). Allow me to explain:
- Interfaces. Maybe you’re used to TDD concepts of suites and unit tests, or perhaps you prefer BDD ideas of behavior specifications with
describeandshould. Mocha lets you use both approaches. - Reporters. Running your test will generate reports of the results, and you can format these results using various reporters. For example, if you need to feed a continuous integration server, you’ll find a reporter to do just that.
- Lack of an assertion library. Far from being a problem, Mocha was designed to let you use the assertion library of your choice, giving you even more flexibility. You have plenty of options, and this is where Chai comes into play.
Chai is a flexible assertion library that lets you use any of the three major assertion styles:
assertThis is the classic assertion style from old-school TDD. For example:assert.equal(variable, "value");expectThis chainable assertion style is most commonly used in BDD. For example:expect(variable).to.equal("value");shouldThis is also used in BDD, but I preferexpectbecauseshouldoften sounds repetitive (i.e. with the behavior specification of “it (should do something…)”). For example:variable.should.equal("value");
Chai combines perfectly with Mocha. Using just these two libraries, you can write your tests in TDD, BDD or any style imaginable.
Grunt
Grunt enables you to automate build tasks, anything including simple copying-and-pasting and concatenation of files, template precompilation, style language (i.e. SASS and LESS) compilation, unit testing (with Mocha), linting and code minification (for example, with UglifyJS or Closure Compiler). You can add your own automated task to Grunt or search the registry, where hundreds of plugins are available (once again, using a tool with a great community behind it pays off). Grunt can also monitor your files and trigger actions when any are modified.
RequireJS
RequireJS might sound like just another way to load modules with the AMD API, but I assure you that it is much more than that. With RequireJS, you can define dependencies and hierarchies on your modules and let the RequireJS library load them for you. It also provides an easy way to avoid global variable space pollution by defining all of your modules inside functions. This makes the modules reusable, unlike namespaced modules. Think about it: If you define a module like Demoapp.helloWordModule and you want to port it to Firstapp.helloWorldModule, then you would need to change every reference to the Demoapp namespace in order to make it portable.
RequireJS will also help you embrace the dependency injection pattern. Suppose you have a component that needs an instance of the main application object (a singleton). From using RequireJS, you realize that you shouldn’t use a global variable to store it, and you can’t have an instance as a RequireJS dependency. So, instead, you need to require this dependency in your module constructor. Let’s see an example.
In main.js:
define(
["App","module"],
function(App, Module){
var app = new App();
var module = new Module({
app: app
})
return app;
}
);
In module.js:
define([],
function(){
var module = function(options){
this.app = options.app;
};
module.prototype.useApp = function(){
this.app.performAction();
};
return module
}
);
Note that we cannot define the module with a dependency to main.js without creating a circular reference.
CoverJS
Code coverage is a metric for evaluating your tests. As the name implies, it tells you how much of your code is covered by your current test suite. CoverJS measures your tests’ code coverage by instrumenting statements (instead of lines of code, like JSCoverage) in your code and generating an instrumented version of the code. It can also generate reports to feed your continuous integration server.
Conclusion
Full-stack JavaScript isn’t the answer to every problem. But its community and technology will carry you a long way. With JavaScript, you can create scalable, maintainable applications, unified under a single language. There’s no doubt, it’s a force to be reckoned with.